Amharic Normalization & Canonical Representation
Canonical pipeline: Input ↔ Normalization ↔ CAR ↔ Output
Deterministic orthographic normalization framework for Amharic, featuring a reversible canonical representation (CAR), ambiguity-aware Latin decoding, and bidirectional punctuation standardization.
Problem
Amharic digital text suffers from inconsistent transliteration, mixed-script input, punctuation variation, and ambiguous Latin decoding. Existing tools silently guess interpretations, leading to incorrect or unstable downstream processing.
Approach
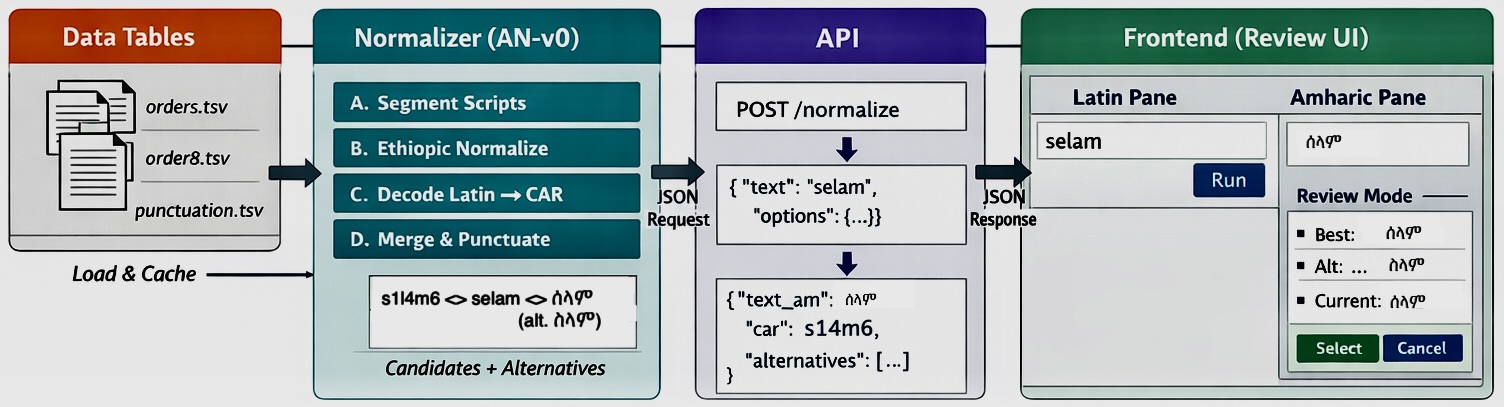
This project introduces a layered architecture for Amharic text processing. At its core is CAR v0 — a strictly bijective canonical encoding of Ethiopic characters. Every character maps to exactly one canonical token, ensuring reversibility and structural stability.
On top of CAR sits AN-v0, a normalization layer capable of handling Ethiopic Unicode, Latin transliteration, and mixed-script input. Ambiguity in Latin decoding is surfaced explicitly via alternatives and confidence scoring rather than silently collapsed.
A bidirectional punctuation normalization layer standardizes Ethiopic marks (። ፣ ፤ ፥ ፦) and implements a context-aware “smart period” rule for abbreviations and decimals.
Impact
The system functions as a canonical preprocessing layer for Amharic NLP pipelines, localization systems, and educational tools. By reducing orthographic noise and enforcing deterministic encoding, it stabilizes tokenization, improves dataset quality, and enables reversible text transformations.
Tools and Methods
- Python
- FastAPI
- React / Vite
- Canonical encoding design
- Bidirectional transliteration
- Linguistic normalization